Note for Neural Networks (2)
Gradient descent
reduce the error between the anticipated and realistic output
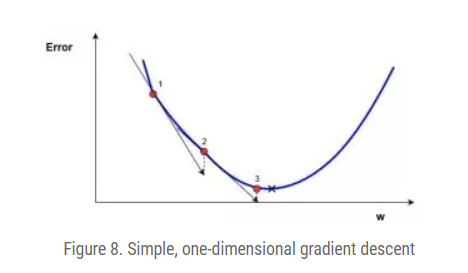 Here $w_{new}$ denotes the new $w$ position, $w_{old}$ denotes the current or old $w$ position, $\nabla error$ is the gradient of the error at $w_{old}$ and $\alpha$ is the step size.
Here $w_{new}$ denotes the new $w$ position, $w_{old}$ denotes the current or old $w$ position, $\nabla error$ is the gradient of the error at $w_{old}$ and $\alpha$ is the step size.
Example gradient descent (original function after gradient is $4x^3 - 9x^2$):
x_old = 0
x_new = 6
gamma = 0.01
precision = 0.00001
def df(x):
y = 4 * x ** 3 - 9 * x ** 2
return y
while abs(x_new - x_old) > precision:
x_old = x_new
x_new += -gamma * df(x_old)
print("The local minimum occurs at %f" % x_new)
The cost function :
The cost function for a training pair $(x^z, y^z)$ in a neural network is: This is the cost function of the $z_{th}$ sample where $h^{(n_l)}$ is the output of the final layer
The total cost is: Gradient descent in neural networks
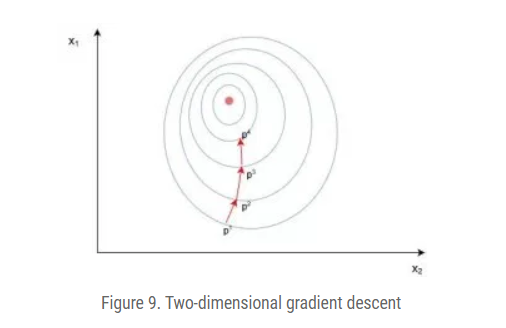
Two dimensional Gradient Descent
Backpropagation in depth (Math Part.)
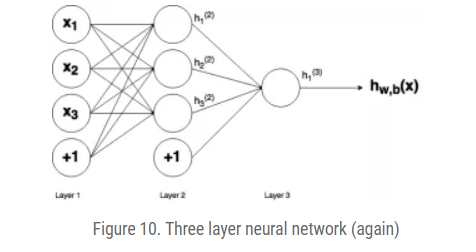
The output of the NN: Simplify $h_1^{(3)} = f(z_1^{(2))})$ by defining $z_1^{(2)}$ as: Then apply gradient descent, we need to calculate the gradient, take the $w_{12}^{(2)}$ as an example Start with the last term Then the second term The derivative of sigmoid is
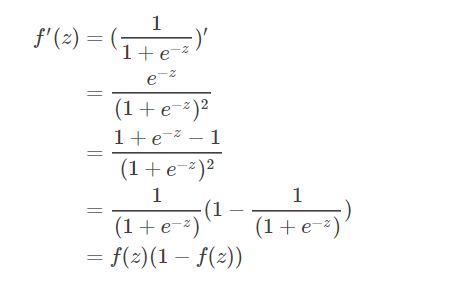
The loss function Let $u=||y_1-h_1^{(3)}(z_1^{(2)})||$ and $J=\frac{1}{2}u^2$
Using $\frac{\partial J}{\partial h} = \frac{\partial J}{\partial u}\frac{\partial u}{\partial h}$ Induce another token Then the derivative can be conclude as
Vectorization of backpropagation
$s_l$ is the number of nodes in layer $l$
where ∙ symbol in the above designates an element-by-element multiplication (called the Hadamard product), not a matrix multiplication.
Reference:
[1]. https://adventuresinmachinelearning.com/neural-networks-tutorial/